
编译原理-引论
程序设计语言
- 机器语言
- 每一个具体的计算机系统都具有自己的指令系统
- 以0,1代码表示的机器指令所构成的语言
- 汇编语言
- 适当的助记符来表示指令中的操作和操作数
- 如含有:add、mov …
- 高级语言
- 其表示方法更接近于待解问题的表示方法
- 定义数据、描述运算、控制流程、传输数据
- 如:C、FORTRAN、PASCAL、C++、JAVA
程序设计语言的翻译
翻译程序(Translator)
- 将某一种语言描述的程序(源程序——Source Program)翻译成等价的另一种语言描述的程序(目标程序——Object Program)的程序。

翻译程序 包含 解释程序 和 编译程序 两种
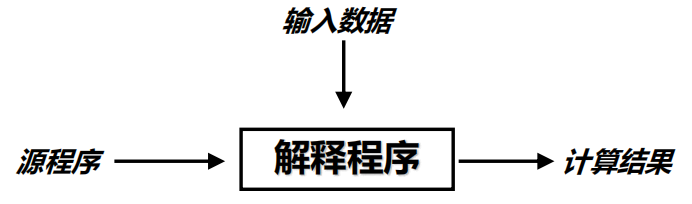
解释程序(Interpreter)
- 边解释边执行:不断读取源程序的语句,解释语句,读取此语句需要的数据,根据执行结果读取下一条语句,继续解释执行,直到返回结果
- 类似于自然语言翻译的同声传译
编译程序(Compiler)
- 将源程序完整地转换成机器语言程序或汇编语言程序,然后再处理、执行的翻译程序
- 高级语言程序 → 汇编/机器语言程序
- 类似于自然语言翻译的通篇笔译
其他翻译程序
- 汇编程序(Assembler)
- 源程序是 汇编程序,目标程序是 机器程序
- 交叉汇编程序(Cross Assembler)
- 源程序是 汇编程序,目标程序是 另一台机器的 机器程序
- 反汇编程序(Disassembler)
- 源程序是 机器程序,目标程序是 汇编程序
- 交叉编译程序(Cross Compiler)
编译系统
编译系统 = 编译程序 + 运行系统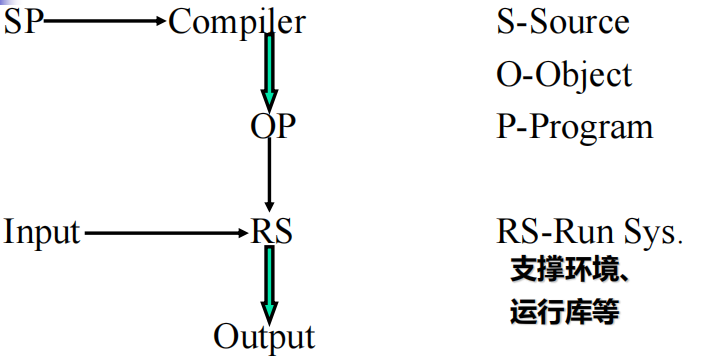
编译程序的总体结构
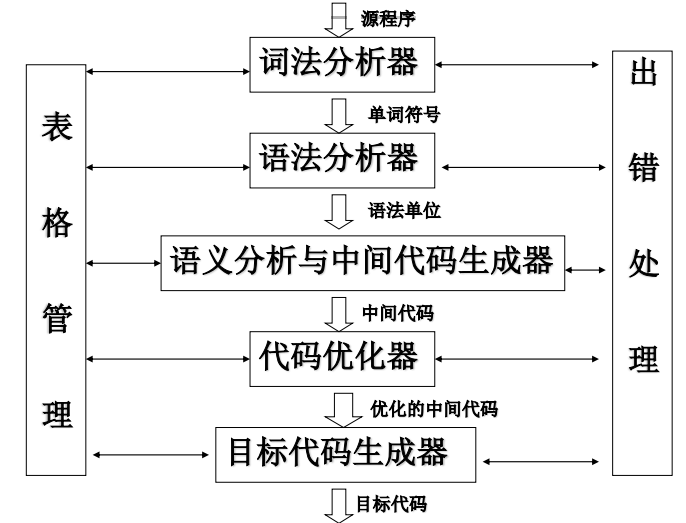
- 模块分类:
- 分析:词法分析、语法分析、语义分析
- 综合:中间代码生成、代码优化、目标代码生成
- 辅助:符号表管理、出错处理
- 8项功能对应8个模块
词法分析
定义
词法分析由词法分析器(Lexical Analyzer)完成,词法分析器又称为扫描器(Scanner)
词法分析器从左到右扫描组成源程序的字符串,并将其转换成单词串;同时要:查词法错误,进行标识符登记(符号表管理)。
输入:字符串
输出:(种别码,属性值)——序对
- 属性值——token的机内表示
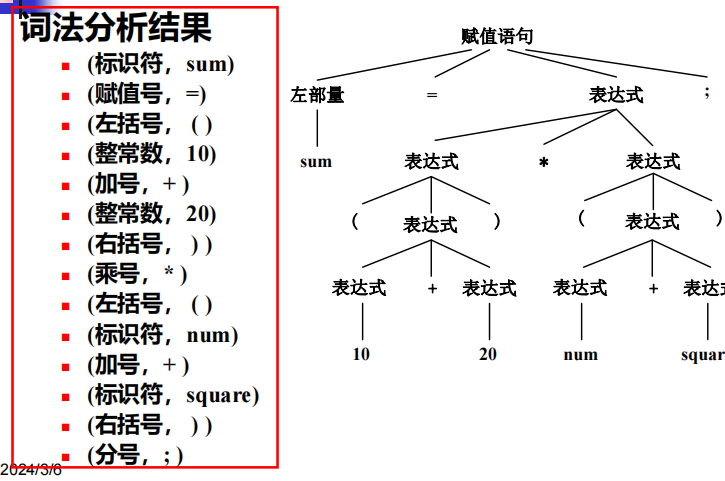
例子:
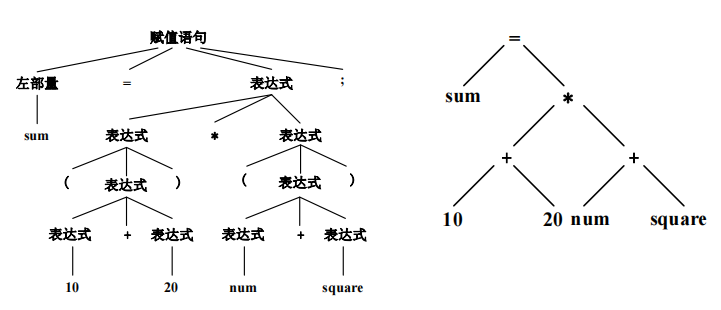
输入:sum=(10+20) * (num+square);
输出: (标识符,sum) (赋值号,=) (左括号,()
(整常数,10) (加号,+ ) (整常数,20)
(右括号,)) (乘号,* ) (左括号,()
(标识符,num) (加号,+ ) (标识符,square)
(右括号,)) (分号,;)
语法分析
语法分析由语法分析器(Syntax Analyzer)完成,语法分析器又叫Parser。
功能:
- Parser实现“组词成句”: 将词组成各类语法成分,例如因子、项、表达式、语句、子程序…
- 构造分析树
- 指出语法错误
- 指导翻译
输入:token序列
输出:语法成分
语义分析
- 语义分析(semantic analysis)一般和语法分析同时进行,称为语法制导翻译
- 功能:分析由语法分析器识别出来的 语法成分的语义
- 获取标识符的属性:类型、作用域等
- 语义检查:运算的合法性、取值范围等
- 子程序的静态绑定:代码的相对地址
- 变量的静态绑定:数据的相对地址
中间代码生成
- 语义分析通常以中间代码形式表达操作
- 中间代码的特点
- 简单规范
- 与机器无关
- 易于优化与转换

代码优化(optimization)
- 对中间代码进行优化处理,使程序运行能够 尽量节省存储空间,更有效地利用机器资源,使得程序的运行速度更快,效率更高
- 这种优化变换必须是等价的。
- 分为(与机器无关的优化)和(与机器有关的优化)两种
与机器无关的优化
可以理解为 算法
局部优化
- 常量合并:常数运算在编译期间完成,如 8+9*4
- 公共子表达式的提取
全局优化
- 主要是指循环优化
- 强度削减:用较快的操作代替较慢的操作
- 代码外提:将循环中不变的计算移出循环
与机器有关的优化
可以理解为 组成原理 和 体系结构
- 寄存器的利用
- 将常用量放入寄存器,以减少访问内存的次数
- 体系结构
- SIMD 、MIMD、SPMD、向量机、流水机
- 任务划分
- 按运行的算法及体系结构,划分子任务(MPMD)
- 存储策略
- 根据算法访存的要求安排:Cache、并行存储体系——减少访问冲突
存储层次
- CPU寄存器
- 保存着最常用的数据,0 个周期访问数据
- 高速缓冲存储器
- 靠近CPU的小的、快速的存储器,1-30个周期访问数据
- 主存储器
- 存储系统和进程运行所需的数据和指令,50-200个周期访问数据
- 磁盘
- 最主要存储设备,10,000,000个周期访问数据
目标代码生成
- 编译程序的最后一个阶段
- 为中间代码中出现的运算对象分配存储单元、寄存器等
- 将中间代码转换成目标机上的机器指令代码或汇编代码
- 对于确定源语言的各种语法成分,确定目标代码结构(机器指令组/汇编语句组)
- 制定从中间代码到目标代码的翻译策略或算法
错误处理
- 进行各种错误的检查、报告、纠正,以及相应的续编译处理(如:错误的定位与局部化)
- 词法分析阶段:拼写方面的错误,出现非法字符等
- 语法分析阶段:表达式、句子或程序结构等错误
- 语义分析阶段:类型匹配错误、参数匹配错误、非法转移问题等
表格管理
- 管理各种符号表(常数、标号、变量、过程、结构……),查、填源程序中出现的符号和编译程序生成的符号,为编译的各个阶段提供信息。
- Hash表、链表等各种表的查、填技术
- “数据结构与算法” 课程的应用
编译程序的组织
- 根据系统资源的状况、运行目标的要求等,可以将一个编译程序设计成多**遍(Pass)**扫描的形式,在每一遍扫描中,完成不同任务。
- 如:首遍构造语法树,二遍处理中间表示,增加信息等
- 遍可以和阶段相对应,也可以和阶段无关
- 遍数量的优化
- 根据语言、系统追求的目标、计算机的资源状况等决定
多遍扫描
- 本遍扫描的结果作为下一遍扫描的输入,本遍扫描中得到的信息在下一遍扫描中也有效,容易获得更优化的程序
- 可以将词法分析、语法分析、语义分析和中间代码生成做成一遍;
- 将代码优化做成一遍;
- 将目标代码生成做成一遍
- 增加内存访问次数,可能增加外部存储的访问次数
单遍扫描
- 分析所需的信息可能目前尚未掌握,导致产生的目标程序难以达到最优
编译程序的设计目标
- 规模小、速度快、诊断能力强、可靠性高、可移植性好、可扩充性好
- 目标程序也要规模小、执行速度快
- 为了提高可移植性,将编译程序划分为前端和后端
前端
- 与源语言有关、与目标机无关的部分
- 词法分析、语法分析、语义分析与中间代码生成、与机器无关的代码优化
- 对于某一种高级语言在不同机器上的编译系统,前端的处理基本是一样的,前端部分可被复用,只需要针对不同的机器构建后端就可以
后端
- 与目标机有关的部分
- 与机器有关的代码优化、目标代码生成
- 在某一种机器上实现多种高级语言的编译系统,后端部分可以被复用,只需要针对不同高级语言构建前端就可以
编译程序的生成
- 编译程序也是运行在计算机上的程序
T形图
表示语言翻译的T形图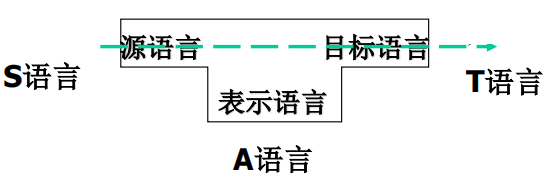
一个用A语言描述的编译程序,它将S语言源程序翻译成了T语言目标程序
自展
- 问题一:如何直接在一个机器上实现C语言编译器?
- 解决:
- 用汇编语言实现一个C子集的编译程序
- 用汇编程序处理该程序,得到(可直接运行)
- 用C子集编制C语言的编译程序
- 用编译,得到
移植
- 问题二:A机上有一个C语言编译器,是否可利用此编译器实现B机上的C语言编译器?
- 条件:A机有C 语言的编译程序
- 目的:实现B机的C语言的编译
- 解决:
- 用C语言编制B机的C编译程序
- (A机C编译器)编译,得到在A机上可运行的
- (A机的)编译,得到B机上可运行的编译器
本机编译器的利用
- 问题三: A机上有一个C语言编译器,现要实现一个新语言NEW的编译器?
- 解决:
- 用C编写NEW的编译器,并用C编译器编译它
编译程序的自动生成
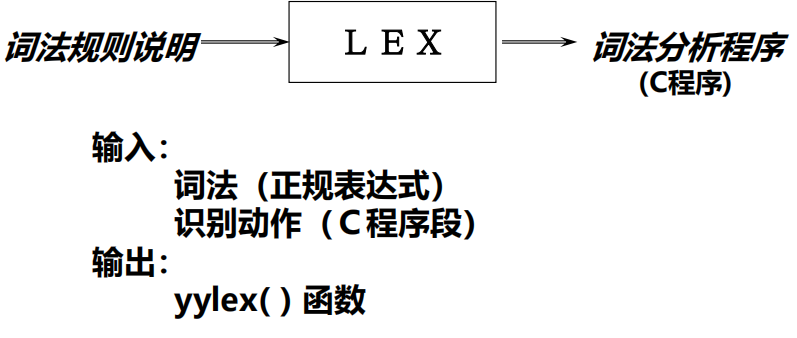
词法分析器的自动生成程序
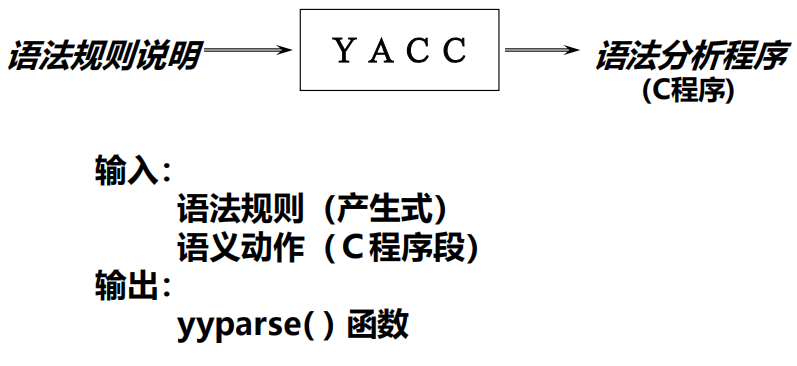
语法分析器的自动生成程序
本博客所有文章除特别声明外,均采用 CC BY-NC-SA 4.0 许可协议。转载请注明来自 Escapeey`Blog!




评论




