
编译原理-词法分析
词法分析器的功能
- 功能:输入源程序,输出单词符号。即:把构成源程序的字符串转换成“等价的”单词序列
- 根据词法规则识别及组合单词,进行词法检查
- 对数字常数完成数字字符串到二进制数值的转换
- 删去空格和注释等不影响程序语义的字符
单词的分类与表示&词法分析器的输出
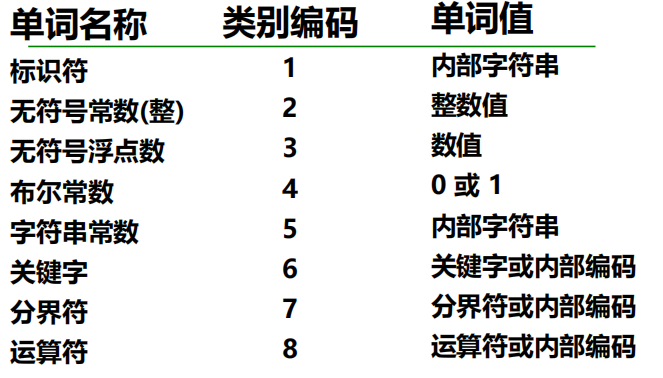
单词的内部形式
二元组 (种别, 属性值)
- 种别:表示种类(可以用整数编码或宏)
- 属性值:不同的单词不同的值
按单词种类分类
固定数量单词采用一符一类
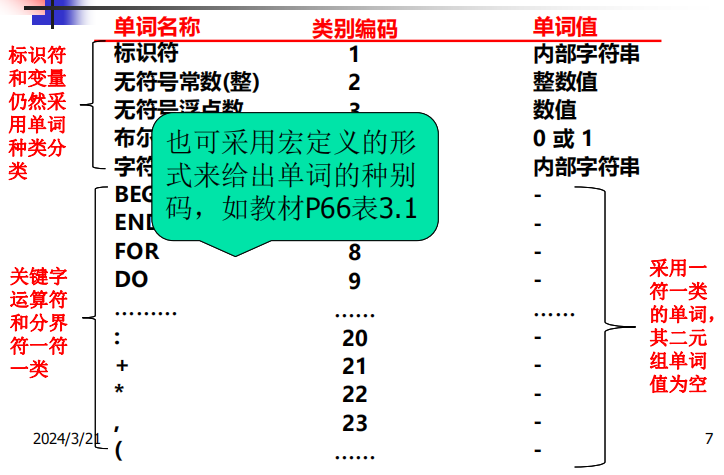
存储方式
问题:如何存储标识符和常量的属性值
- 方法1:用标识符和常量本身的值表示
- 方法2:用指针表示
本身的值
- 不同值存储空间长度不同
- 往往需要对长度加以限制,意味着要截断
用指针表示
- 指针长度固定->属性值的长度相同
- 间接访存->由于词法分析器要兼顾符号表的查填和维护,间接访存增加负担
例子

源程序的输入缓冲与预处理
源程序以字符流形式存储于外部介质
为正确识别单词,编译程序需要一系列相关处理
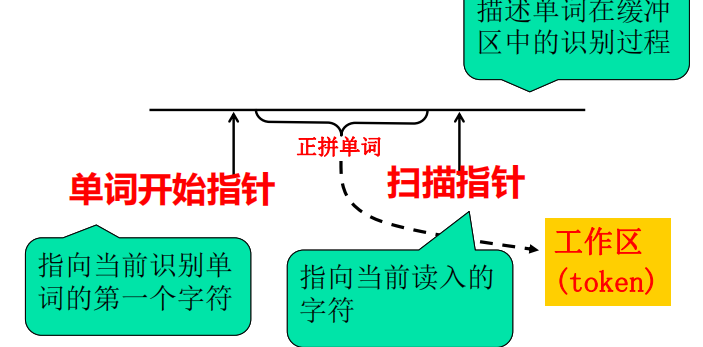
- 超前搜索和回退
- 标识符的识别,或双字符运算符(**, <=, <>)
- 回退操作修正超前搜索
- 缓冲区
- 假定源程序存储在磁盘上,这样每读一个字符就需要访问一次磁盘,效率显然是很低的。
- 一次性从磁盘读取给定大小的部分源程序
- 空白字符的剔除
- 剔除源程序中的无用符号、空格、换行、注释等
输入缓冲区
- 单缓冲区存在的问题
- 缓冲区内容用完后,等待新的输入需要等待,应该避免类似的等待
- 缓冲区尾部可能只包含单词的一部分,载入下一部分程序时,当前缓冲区的内容被覆盖,最坏情况下可识别的单词长度只能为1,而且无法执行超前搜索
- 采用双缓冲区
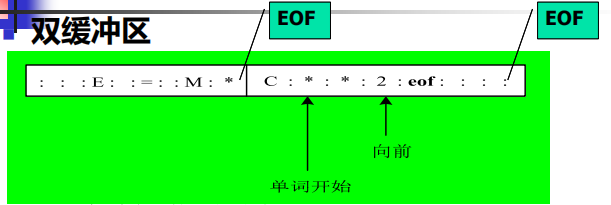
1 | if forward在缓冲区第一部分末尾 then |
- 令缓冲区大小为2N,则双缓冲区的每一个大小是N,双缓冲技术将可识别单词的长度扩展到N
- 每次移动向前指针都需要做两次测试:
- 是否到缓冲区末尾
- 当前字符是否是EOF
- 修正方法:采用带标记缓冲区,即两个缓冲区的末尾处各设置一个“EOF”标志
- 如果当前字符是“EOF”,就再判断是否到达缓冲区末尾,将移动向前指针需要的两次测试减少到 (N+1)/N
词法分析阶段的错误处理
非法字符检查
- 维护一个合法字符集合,对于每一个输入字符,判断该字符是否属于该字符集合
单词拼写错误
- 关键字拼写词法分析阶段无法检测,待语法分析阶段发现错误
- 标识符拼写错误,如3b78,处理方法有两种
- 识别出整数3、标识符b78
- 错误的标识符
注释或字符常量不封闭
- 会错误地将后续所有源程序看作是注释或者是字符串的一部分,影响正常程序分析
- 对注释或字符串长度加以限制,如注释长度不超过1行,字符串长度最大是256
变量重复说明
- 当词法分析器兼顾符号表的查填工作时才能发现该错误
- 为了指出错误的位置,必须对源程序进行行列计数
- 出错信息可以夹在源程序发生错误的地方(便于修改,但容易弄乱源程序)
- 出错信息也可以收集起来统一处理
错误恢复与续编译
- 词法分析阶段的错误使得编译无法继续进行,需要采取措施使得编译继续下去
- 方法
- 错误校正:极其困难
- 紧急方式恢复(panic-mode recovery):反复删掉剩余输入最前面的字符,直到词法分析器能发现一个正确的单词为止。
词法分析器的位置
- 独立地完成对源程序的一遍扫描,将单词序列以中间文件形式存储,作为语法分析的输入
- 简化编译器的设计
- 提高编译器的效率
- 增强编译器的可移植性
- 作为语法分析器的一个子程序
- 整个编译程序简单紧凑
单词的描述
- 根据正则文法构造等价的正则表达式
- 将正则表达式转换成等价的正则文法
- 构造有穷状态自动机
- 正则表达式转换为状态转换图
单词的识别
有穷状态自动机与单词识别的关系
- 识别不同进制数的状态图 P91
- 单词识别的状态转换图表示 P96
- 利用状态转换图识别单词 P98
- 由正则文法构造状态转换图 P101
- 状态转换图的实现 P107
- 状态矩阵
- 邻接表
- 四个数组组成的结构,既可以实现数据压缩存储,又可以实现元素的快速访问 P117
词法分析程序的自动生成
本博客所有文章除特别声明外,均采用 CC BY-NC-SA 4.0 许可协议。转载请注明来自 Escapeey`Blog!




评论




